


 光環助手2025v5.38.8官方最新版手機工具立即下載
光環助手2025v5.38.8官方最新版手機工具立即下載 微店輸入法v1.4.0 安卓版手機工具立即下載
微店輸入法v1.4.0 安卓版手機工具立即下載 vivo應用商店v9.13.20.0官方最新版手機工具立即下載
vivo應用商店v9.13.20.0官方最新版手機工具立即下載 Freeme OS輕係統V3.1.0官方免費版手機工具立即下載
Freeme OS輕係統V3.1.0官方免費版手機工具立即下載 愛吾遊戲寶盒安卓版V2.4.0.1手機工具立即下載
愛吾遊戲寶盒安卓版V2.4.0.1手機工具立即下載 kingroot一鍵root工具v3.0.1.1109 最新pc版手機工具立即下載
kingroot一鍵root工具v3.0.1.1109 最新pc版手機工具立即下載 雲電腦appv5.9.9.1官方版手機工具立即下載
雲電腦appv5.9.9.1官方版手機工具立即下載 壁虎數據恢複安卓版V2.5.6官方版手機工具立即下載
壁虎數據恢複安卓版V2.5.6官方版手機工具立即下載 天天酷跑v1.0.126.0安卓版
天天酷跑v1.0.126.0安卓版
 sky光遇北覓全物品解鎖版v0.28.5(313329)最新版
sky光遇北覓全物品解鎖版v0.28.5(313329)最新版
 天天愛消除2024最新版v2.37.0.0Build32
天天愛消除2024最新版v2.37.0.0Build32
 原神手遊v5.4.0_30057195_30231699最新版
原神手遊v5.4.0_30057195_30231699最新版
 可口的咖啡美味的咖啡無限鈔票免廣告版v0.1.4最新版
可口的咖啡美味的咖啡無限鈔票免廣告版v0.1.4最新版
 王者榮耀國際版honor of kings官方最新版v10.20.3.1安卓版
王者榮耀國際版honor of kings官方最新版v10.20.3.1安卓版
 手機京東appv15.0.60安卓版
手機京東appv15.0.60安卓版
 UC瀏覽器安卓版v17.4.2.1373官方最新版
UC瀏覽器安卓版v17.4.2.1373官方最新版
 酷我音樂盒2022最新安卓版V11.1.6.2官方版
酷我音樂盒2022最新安卓版V11.1.6.2官方版
 MOMO陌陌2022最新版本V9.15.10官方版
MOMO陌陌2022最新版本V9.15.10官方版
 全民k歌2022年最新版V9.5.38.278 官方版
全民k歌2022年最新版V9.5.38.278 官方版
 小紅書app2024最新版v8.72.0安卓版
小紅書app2024最新版v8.72.0安卓版
DeepSeek華為版最新版本是杭州深度求索官方推出的AI助手,其總參數超過600B的DeepSeek-V3大模型一經開源即在海內外引起震動。這款AI助手具有多項性能指標,可與海外頂尖模型相媲美,以其更快的速度和更強大全麵的功能,為用戶答疑解惑,助力高效美好的生活。
官方說明
DeepSeek 官方推出的 AI 助手,免費體驗與全球領先 AI 模型的互動交流。
使用一經開源即在海內外引起震動、總參數超過 600B 的 DeepSeek-V3 大模型,多項性能指標對齊海外頂尖模型,用更快的速度、更加全麵強大的功能為你答疑解惑,助力高效美好的生活。
軟件特色
智能對話
高智商模型,順滑對話體驗
深度思考
先思考後回答,解決推理難題
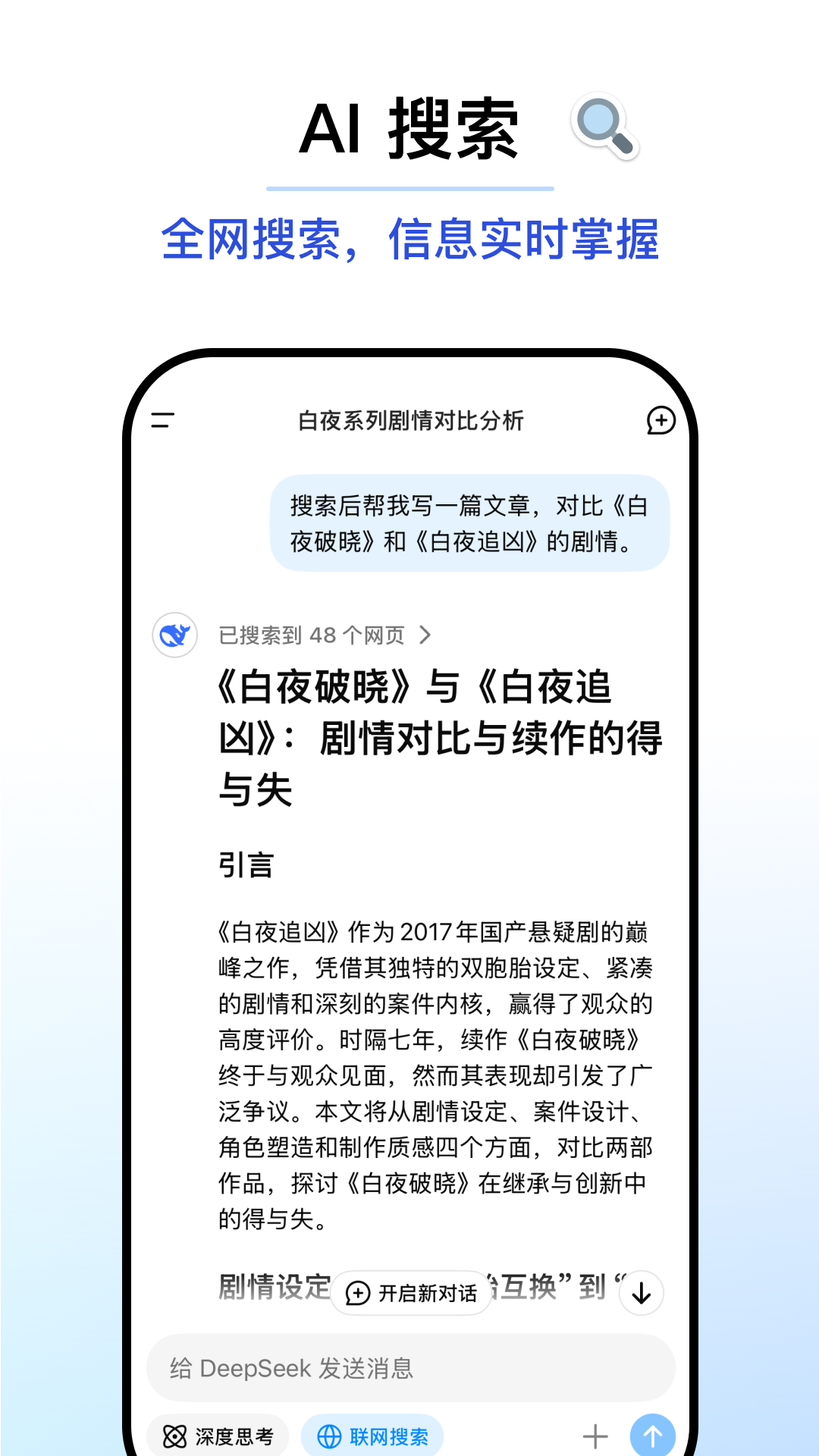
AI 搜索
全網搜索,信息實時掌握
文件上傳
閱讀長文檔,高效提取信息
DeepSeek V3模型驅動
App背後的模型正是前段時間爆火的DeepSeek V3——以1/11算力訓練超越Llama 3的模型,震撼一整個AI圈。
它是一個參數量為671B的MoE模型,激活37B,在14.8T高質量token上進行了預訓練。
它發布即完全開源,在多項測評上,DeepSeek V3達到了開源SOTA,超越Llama 3.1 405B,能和GPT-4o、Claude 3.5 Sonnet等TOP模型正麵掰掰手腕。
而其價格比Claude 3.5 Haiku還便宜,僅為Claude 3.5 Sonnet的9%。
而如果要平衡性能和成本,它成了DeepSeek官方繪圖中唯一闖進“最佳性價比”三角區的模型。
也正因為之前DeepSeek太受關注,還有一些假冒App,網友們深受其害。
現在總算是有了官方正版可以使用啦~
deepseek和豆包哪個厲害
DeepSeek:專業數據分析與知識挖掘助手
DeepSeek定位為專業場景下的數據分析和知識挖掘工具,專為技術與商業領域設計。
特點與優勢:
強大的數據處理和技術文檔解析能力。提供深入的知識圖譜和報告生成功能。支持多領域的專業知識問答。
適用場景:
適合科研人員、企業決策者和需要深度分析的用戶。?
豆包:輕鬆有趣的社交型助手
豆包定位為一款注重互動性和趣味性的AI助手,非常適合日常聊天和娛樂應用。
特點與優勢:
響應快速,語言風格輕鬆幽默。擅長趣味問答、閑聊和簡單信息查詢。適合需要輕鬆交流或快速生成娛樂內容的用戶。
適用場景:
適合日常生活中的娛樂需求,如調節心情或進行簡單的知識探索。
總體來說,DeepSeek和豆包各有特色,因此,選擇哪個更厲害取決於具體的應用場景和需求。
使用說明
百科知識:DeepSeek-V3 在知識類任務(MMLU, MMLU-Pro, GPQA, SimpleQA)上的水平相比前代 DeepSeek-V2.5 顯著提升,接近當前表現最好的模型 Claude-3.5-Sonnet-1022。
代碼:DeepSeek-V3 在算法類代碼場景(Codeforces),遠遠領先於市麵上已有的全部非 o1 類模型,並在工程類代碼場景(SWE-Bench Verified)逼近 Claude-3.5-Sonnet-1022。
長文本:長文本測評方麵,在DROP、FRAMES 和 LongBench v2 上,DeepSeek-V3 平均表現超越其他模型。
數學:在美國數學競賽(AIME 2024, MATH)和全國高中數學聯賽(CNMO 2024)上,DeepSeek-V3 大幅超過了所有開源閉源模型。
中文能力:DeepSeek-V3 與 Qwen2.5-72B 在教育類測評 C-Eval 和代詞消歧等評測集上表現相近,但在事實知識 C-SimpleQA 上更為領先。
關於我們
DeepSeek Chat:支持自然語言處理、問答係統、智能對話、智能推薦、智能寫作和智能客服等多種任務。能夠理解並回應用戶的各種問題和需求,包括閑聊、知識查詢、任務處理等。提供多語言支持,能夠根據用戶的語氣和情緒調整對話風格。支持文件上傳功能,可掃描讀取圖片或文件中的文字內容。
DeepSeek Coder:專注於編程代碼生成、調試和優化。在編程能力上顯著提升,能夠提供多個解決方案以解決編程瓶頸問題。支持代碼優化和重構任務,提高代碼可讀性和可維護性。模型訓練成本低,支持大規模數據處理。
DeepSeek R1:支持模型蒸餾,蒸餾出的1.5B、7B、8B、14B等小模型非常適合在本地部署,尤其適合資源有限的中小企業和開發者。基於強化學習(RL)驅動,專注於數學和代碼推理,支持長鏈推理(CoT),適用於複雜邏輯任務。
DeepSeek-R1 發布,性能對標 OpenAI o1 正式版
DeepSeek V3:參數量為671億,激活參數為37億。在14.8T高質量token上進行了預訓練,性能表現達到開源SOTA水平,超越Llama 3.1 405B和GPT-4o等頂尖模型,在數學能力方麵表現尤為突出。訓練成本僅需約558萬美元,相比傳統模型大幅降低。完全開源,訓練細節公開。
DeepSeek V2:參數量為236億,激活參數為21億。支持128K上下文窗口,顯存消耗低,每token成本大幅降低。
性能對齊 OpenAI-o1 正式版
DeepSeek-R1 在後訓練階段大規模使用了強化學習技術,在僅有極少標注數據的情況下,極大提升了模型推理能力。在數學、代碼、自然語言推理等任務上,性能比肩 OpenAI o1 正式版。
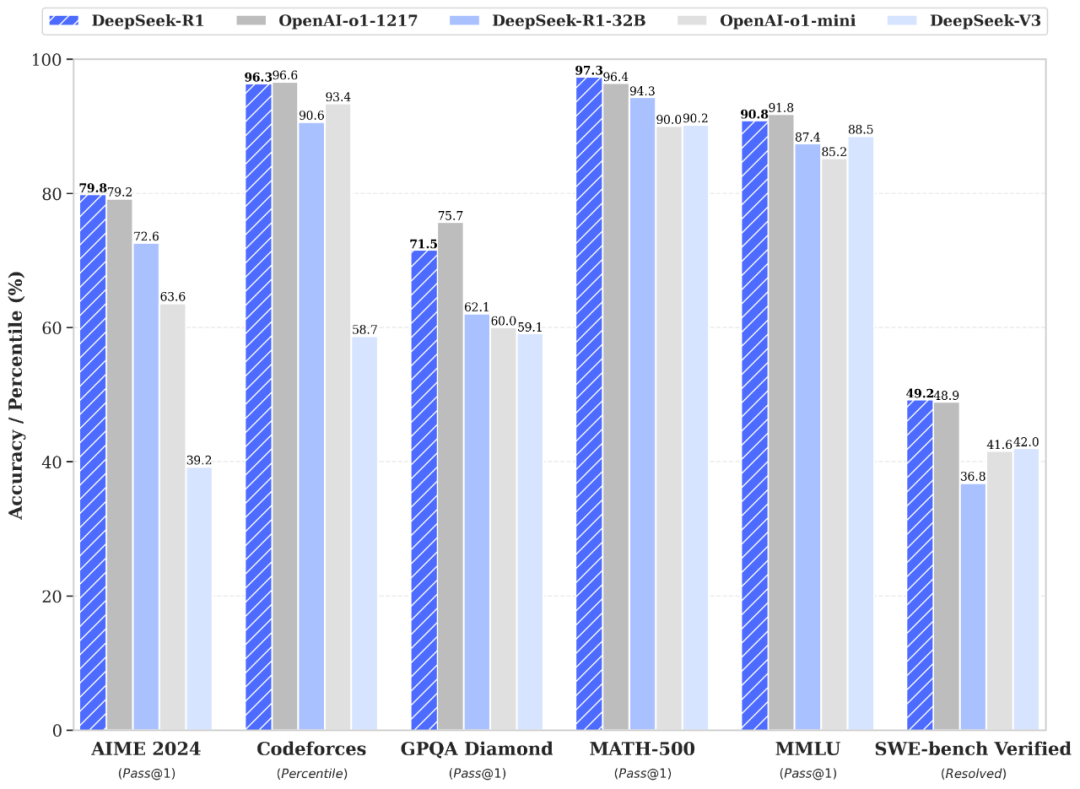
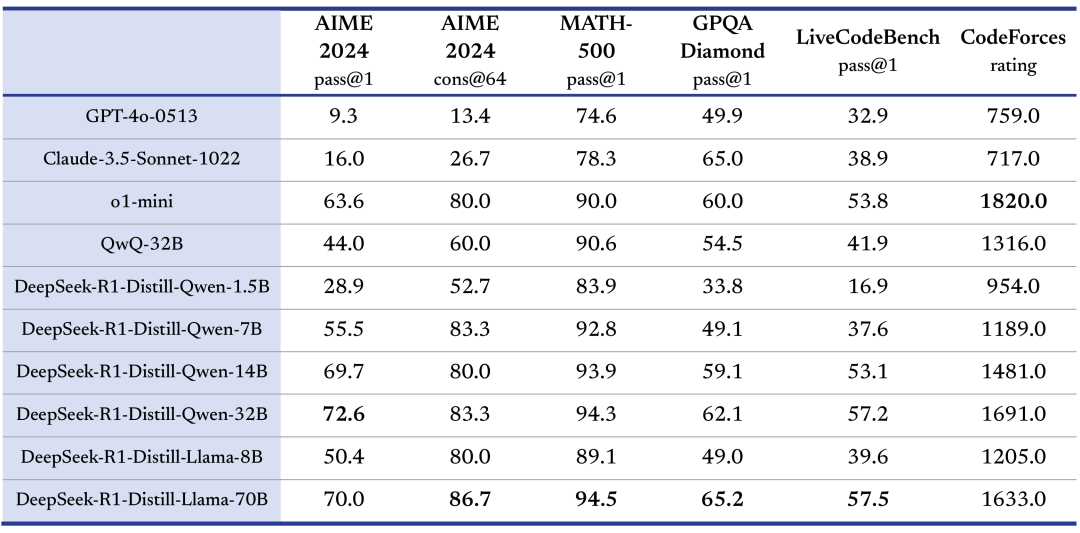
蒸餾小模型超越 OpenAI o1-mini
我們在開源 DeepSeek-R1-Zero 和 DeepSeek-R1 兩個 660B 模型的同時,通過 DeepSeek-R1 的輸出,蒸餾了 6 個小模型開源給社區,其中 32B 和 70B 模型在多項能力上實現了對標 OpenAI o1-mini 的效果。
開放的許可證和用戶協議
為了推動和鼓勵開源社區以及行業生態的發展,在發布並開源 R1 的同時,我們同步在協議授權層麵也進行了如下調整:
模型開源 License 統一使用 MIT。我們曾針對大模型開源的特點,參考當前行業的通行實踐,特別引入 DeepSeek License 為開源社區提供授權,但實踐表明非標準的開源 License 可能反而增加了開發者的理解成本。為此,此次我們的開源倉庫(包括模型權重)統一采用標準化、寬鬆的 MIT License,完全開源,不限製商用,無需申請。
產品協議明確可“模型蒸餾”。為了進一步促進技術的開源和共享,我們決定支持用戶進行“模型蒸餾”。我們已更新線上產品的用戶協議,明確允許用戶利用模型輸出、通過模型蒸餾等方式訓練其他模型。
DeepSeek App與網頁端
登錄DeepSeek官網或官方App,打開“深度思考”模式,即可調用最新版 DeepSeek-R1 完成各類推理任務。
- 安卓版
- PC版
- IOS版



 逐光劇場紅包版app1.0.1最新版立即下載
逐光劇場紅包版app1.0.1最新版立即下載 PMX Pro權限管理高級版下載最新版v1.27-pro立即下載
PMX Pro權限管理高級版下載最新版v1.27-pro立即下載 同城尋秘app安卓版1.1.0最新版立即下載
同城尋秘app安卓版1.1.0最新版立即下載 picwish佐糖appv2.0.4立即下載
picwish佐糖appv2.0.4立即下載 zero Vectras VM數據包下載漢化版zero-v3.0-cn立即下載
zero Vectras VM數據包下載漢化版zero-v3.0-cn立即下載 happyshort短劇app最新版1.4.9官方版立即下載
happyshort短劇app最新版1.4.9官方版立即下載 漢水襄陽新聞客戶端v1.3.5安卓版立即下載
漢水襄陽新聞客戶端v1.3.5安卓版立即下載 DJI Ronin app安卓版v1.9.0官方版立即下載
DJI Ronin app安卓版v1.9.0官方版立即下載 白鴿社區app官方正版v5.24安卓版立即下載
白鴿社區app官方正版v5.24安卓版立即下載 歐易錢包官方app全新版v6.110.0官方版立即下載
歐易錢包官方app全新版v6.110.0官方版立即下載 歐易app官方下載2025最新版v6.110.0官方版立即下載
歐易app官方下載2025最新版v6.110.0官方版立即下載 月鼠小說解鎖會員v4.7.1.1立即下載
月鼠小說解鎖會員v4.7.1.1立即下載 瘋狂刷題app官方正版v1.16.22最新版立即下載
瘋狂刷題app官方正版v1.16.22最新版立即下載 飛藍電視app官方下載最新版本V1.0.1立即下載
飛藍電視app官方下載最新版本V1.0.1立即下載 萬能工具箱app免費下載官方安卓版1.2.6立即下載
萬能工具箱app免費下載官方安卓版1.2.6立即下載 月影劇場app官方正版1.0.1安卓版立即下載
月影劇場app官方正版1.0.1安卓版立即下載 米讀書城官方下載解鎖高級版v2.43.1.0213.1200安卓立即下載
米讀書城官方下載解鎖高級版v2.43.1.0213.1200安卓立即下載 愛給網官方免費下載素材1.0.1立即下載
愛給網官方免費下載素材1.0.1立即下載 deepseek YYDS官方下載最新版
deepseek YYDS官方下載最新版 Deepseek矽基流動手機版
Deepseek矽基流動手機版 DeepSeek API文檔官方提示庫
DeepSeek API文檔官方提示庫 DeepSeek官方提示庫官方版
DeepSeek官方提示庫官方版 DeepSeek穀歌版下載2025官方最新版
DeepSeek穀歌版下載2025官方最新版 deepseek海外版下載2025最新版
deepseek海外版下載2025最新版 小腎魔盒app
小腎魔盒app 人工智能app免費下載
人工智能app免費下載 deepseek訓練模型下載
deepseek訓練模型下載 我在aiapp下載2025官方最新版
立即下載
手機工具
我在aiapp下載2025官方最新版
立即下載
手機工具
 雞樂盒v5.0版本
立即下載
手機工具
雞樂盒v5.0版本
立即下載
手機工具
 旋風免費加速器app安卓版
立即下載
手機工具
旋風免費加速器app安卓版
立即下載
手機工具
 scene工具箱軟件安卓官方最新版本
立即下載
手機工具
scene工具箱軟件安卓官方最新版本
立即下載
手機工具
 雞樂盒7.0無廣告最新版
立即下載
手機工具
雞樂盒7.0無廣告最新版
立即下載
手機工具
 TapTap
立即下載
手機工具
TapTap
立即下載
手機工具
 迅雷av下載2024官方版
立即下載
手機工具
迅雷av下載2024官方版
立即下載
手機工具
 雞樂盒8.0無廣告懸浮窗
立即下載
手機工具
雞樂盒8.0無廣告懸浮窗
立即下載
手機工具
 viggle ai下載安卓版
立即下載
手機工具
viggle ai下載安卓版
立即下載
手機工具
 momo檢測環境異常軟件
立即下載
手機工具
momo檢測環境異常軟件
立即下載
手機工具
熱門評論
最新評論